通过 xAI API 密钥和按量付费模式在 OpenClaw 中配置 Grok 集成。
通过配置 xAI API 端点和令牌成本监控,将 Grok 集成到 OpenClaw 的实操指南。
📅 2026/04/19
Deploy & Ops
探索 部署运维 风格的 OpenClaw 玩法
通过配置 xAI API 端点和令牌成本监控,将 Grok 集成到 OpenClaw 的实操指南。
📅 2026/04/19

OpenClaw 被确立为历史级开源里程碑,并演变为由 NVIDIA 正式交付的全自主企业级 AI 代理。
📅 2026/04/18

通过实施递归封顶、幂等性密钥和事件驱动通知,防止代理工作流失败并降低成本。
📅 2026/04/18

为 MCP 框架全局安装社交媒体同步代理技能。
📅 2026/04/18
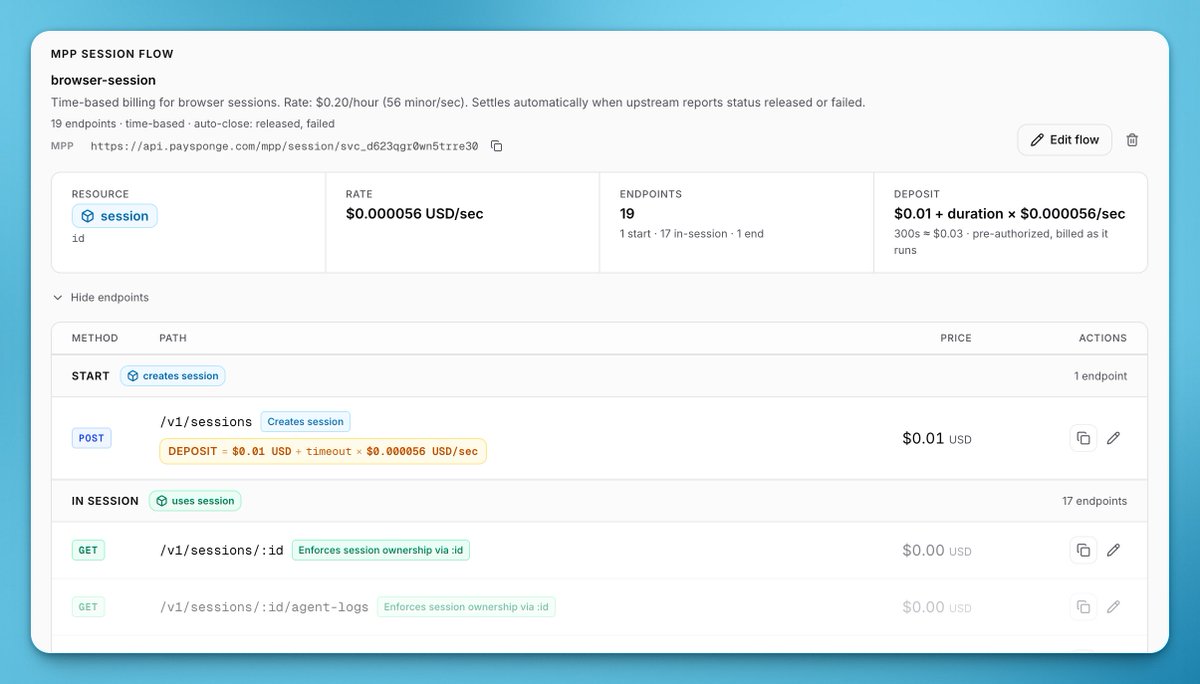
利用 Sponge Gateway 和 MCP 协议为 AI 智能体配置动态计价模型(按请求、按用量、按时长)。
📅 2026/04/18

在 AWS 试错后,将 OpenClaw 迁移至基于 Docker 的 Hostinger VPS 以优化成本并确保稳定性。
📅 2026/04/17

设置带 SSH 权限的 AI 代理并接入 MiniMax 模型进行自动化开发操作。
📅 2026/04/16
利用 CLI 保活工具实现跨国远程自动化工作流监控。
📅 2026/04/16
显示第 1 - 12 至 277 项