Analyzes the economic impact of Anthropic's policy changes on OpenClaw and proposes optimization str
Code Maintenance📅 2026/04/06

#API#Developer#Documentation#GitHub#Manual Trigger#Medium Risk#Reusable#Semi-Automatic#代码仓库#多模型#成本优化#本地部署
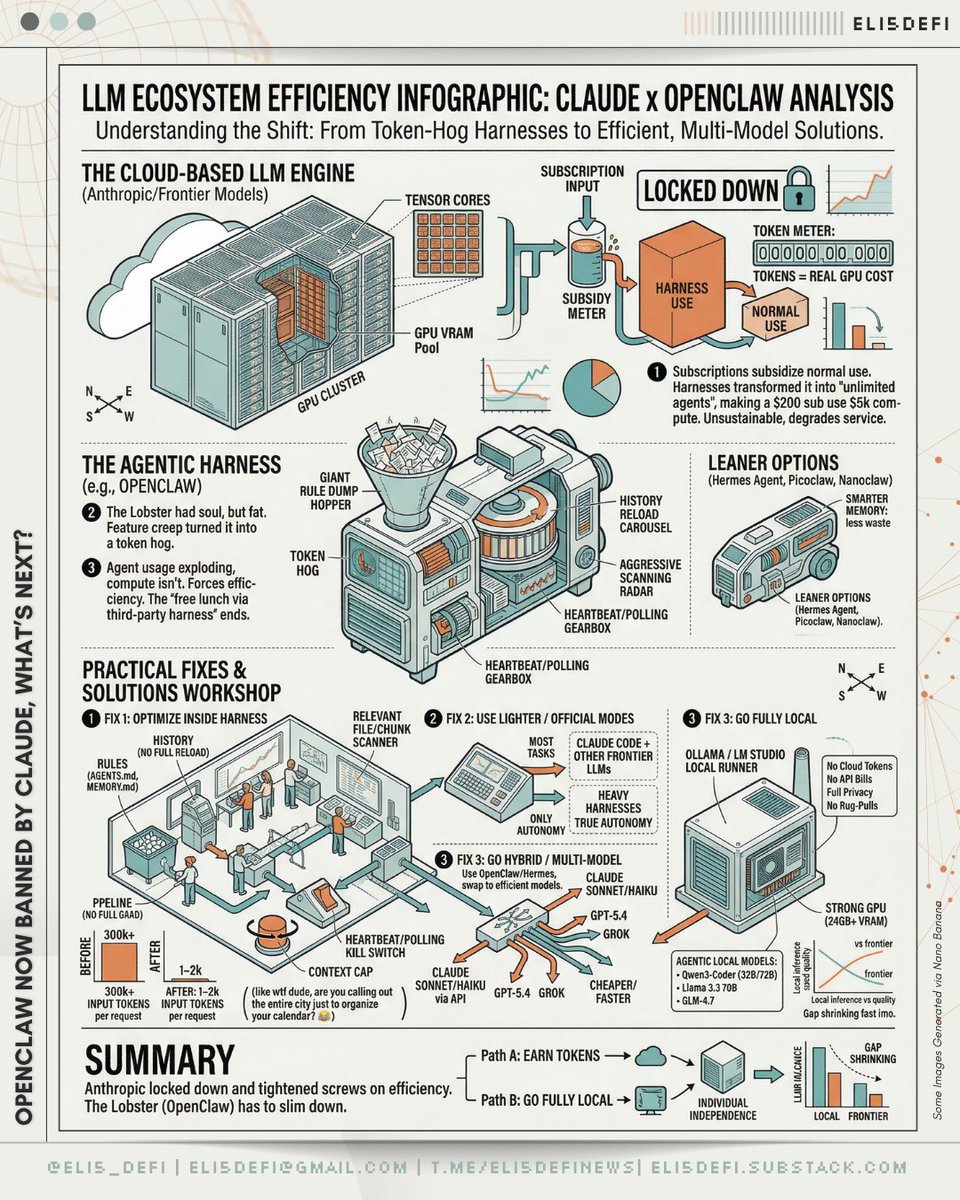
My take on the Claude x OpenClaw situation: ❶ Anthropic is right on the economics Subscriptions subsidize normal use. Harnesses like OpenClaw turned that into “unlimited agents,” where a $200 sub can rack up $5k in compute. That’s not sustainable, and it degrades service for everyone. Tokens = real GPU cost. ❷ The lobster had soul, but it also had fat. Feature creep (polling, aggressive scans, giant rule dumps) turned it into a token hog. New leaner options, Hermes Agent - @NousResearch, Picoclaw and even Nanoclaw, focus on smarter memory with less waste. ❸ Agent usage is exploding, compute isn’t This move forces efficiency instead of living on subsidized tokens. Long-term, open-source wins by going multi-model, but the “free lunch via third-party harness” era was going to end. — Practical fixes for harness users ❶ Optimize inside your harness (do this first): ▸ Put rules in stable files (AGENTS. md, MEMORY. md) ▸ Don’t reload full history ▸ Scan only relevant files/chunks ▸ Kill unnecessary heartbeats/polling ▸ Cap context hard People report reducing input tokens from 300k+ to ~1–2k per request (like wtf dude, are you calling out the entire city just to organize your calendar? 😂). ❷ Use lighter/official modes: Use Claude Code + Other Frontier LLMs for most of tasks; save heavy harnesses for true autonomy. ❸ Go hybrid / multi-model Keep OpenClaw/Hermes, swap to cheaper/faster models or local models (Sonnet/Haiku via API, or GPT-5.4, Grok, etc.). OpenClaw already supports this. ❸ Go fully local with open-source LLMs for true independence. OpenClaw now supports local runners - @ollama and @huggingface: no cloud tokens, no API bills, full privacy, no rug-pulls. Works well with agentic local models like Qwen3-Coder (32B/72B, GLM-4.7 or even Gemma 4. However, you’ll want a strong GPU (24GB+ VRAM for decent speed). Inference is slower than Claude and quality still lags frontier models, but the gap is shrinking fast imo. — Bottom line, Anthropic locked down their stack and tightened the screws on efficiency, forcing the Lobster to slim down. Still, the Lobster survives, now it has to earn its tokens… or go fully local and run free.