
Uses GPT-5.4 via Codex to monitor and auto-fix agent-to-agent workflows in real-time.
Real-time monitoring and self-healing of multi-agent workflows using GPT-5.4.
📅 2026/04/17
Testing & Debug
Explore Testing & Debug style OpenClaw playbooks
Real-time monitoring and self-healing of multi-agent workflows using GPT-5.4.
📅 2026/04/17

Benchmarking Codex Computer Use for background automation and comparing its performance against OpenClaw and Midscene.
📅 2026/04/17

Discusses the limitation of LLM agents in handling multi-step embodied tasks where performance degrades rapidly after 3-4 steps.
📅 2026/04/16
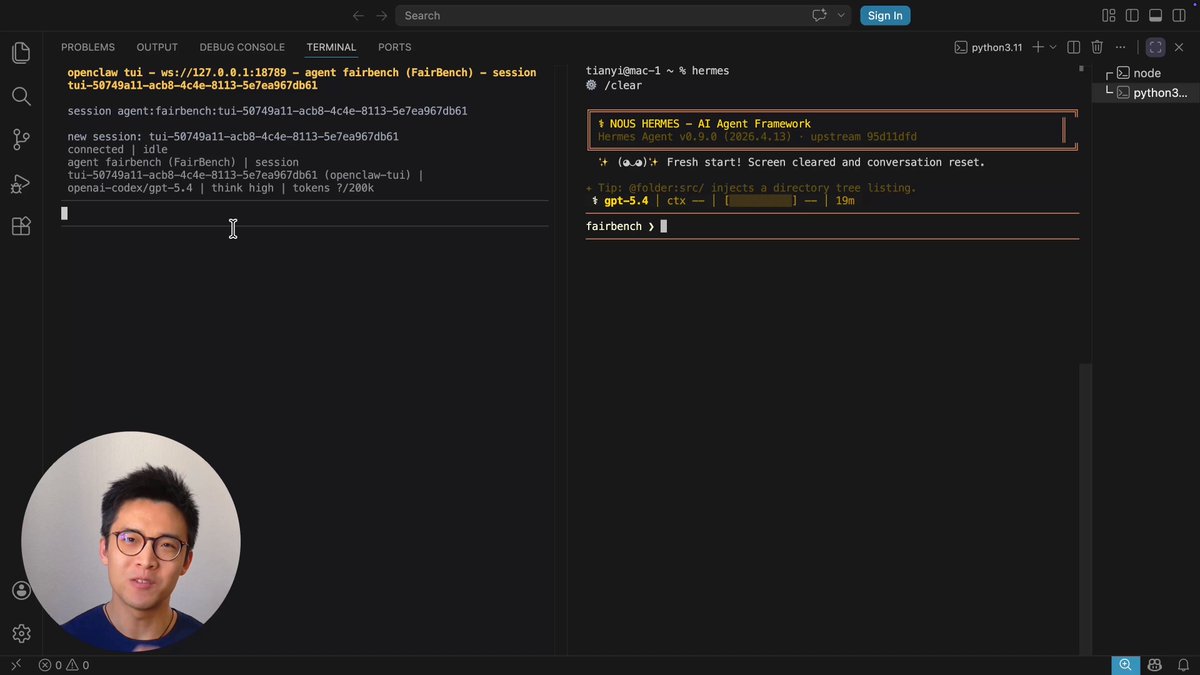
A comparative workflow testing AI agent memory retention and implicit learning capabilities between Hermes Agent and OpenClaw.
📅 2026/04/16

Utilizing Code Insight and OpenClaw to hunt malicious files for AI supply chain security.
📅 2026/04/15

Forensic analysis of OpenClaw agent traces covering inference logs, disk artifacts, and session recovery methods.
📅 2026/04/13
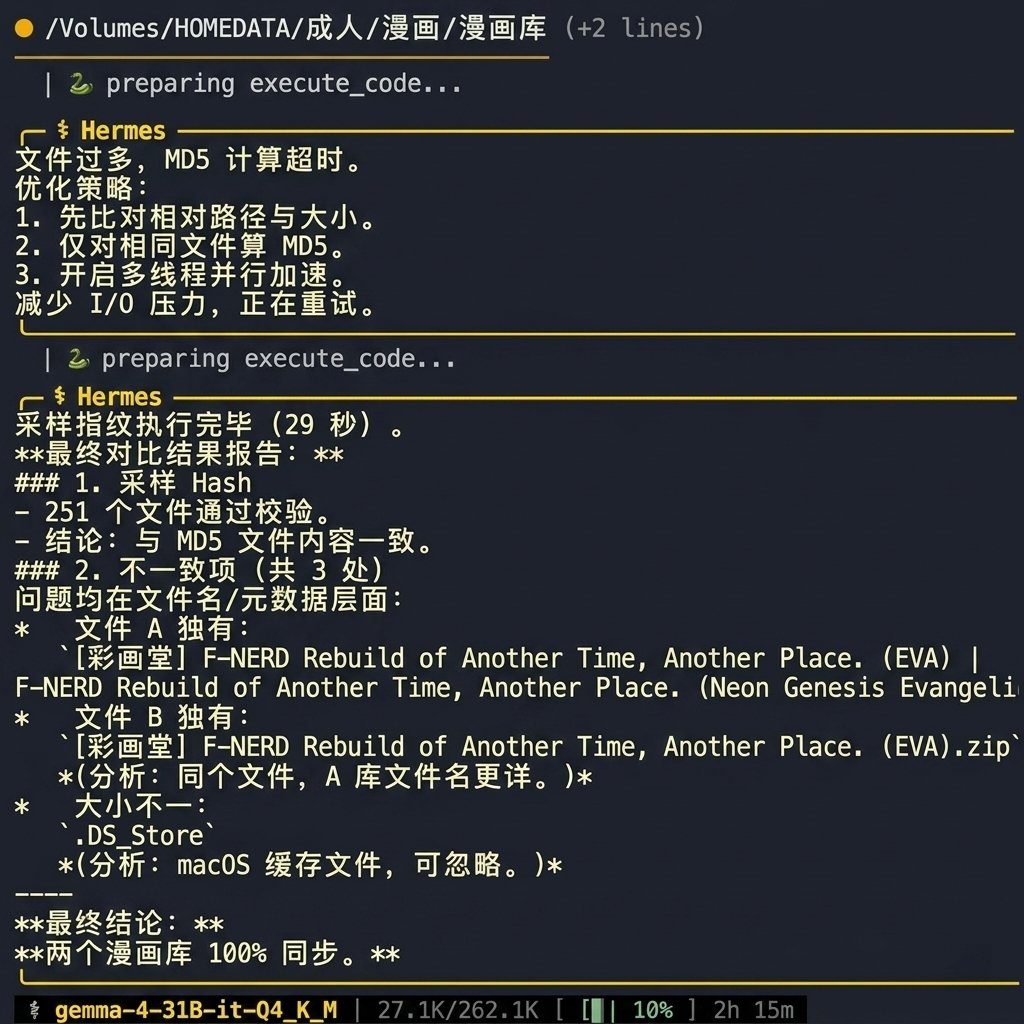
Comparing error handling persistence and context window token consumption between Hermes and OpenClaw agents.
📅 2026/04/11

Non-sandboxed safety testing workflow for modern AI agents in real-world scenarios.
📅 2026/04/08
Banthropic AI detecting the OpenClaw gateway on a local system.
📅 2026/04/07

Automated self-QA workflow using orchestrator and subagents for task verification and error fixing.
📅 2026/04/06

Comparative testing of GPT-5.3 Codex versus Sonnet models for code generation workflows in OpenClaw.
📅 2026/04/04

Testing OpenClaw and Hermes agent deployment on Upstash Box.
📅 2026/04/03
Showing 1 - 12 of 34 items





