其实OpenClaw抓取网页信息的机制很垃圾 要么经常抓不到信息,要么就是抓到一堆垃圾信息,难怪消耗这么多 token。 但今天试用一下推友推荐的 xcrawl,解决这个问题。 安装方式
Finance📅 2026/03/30
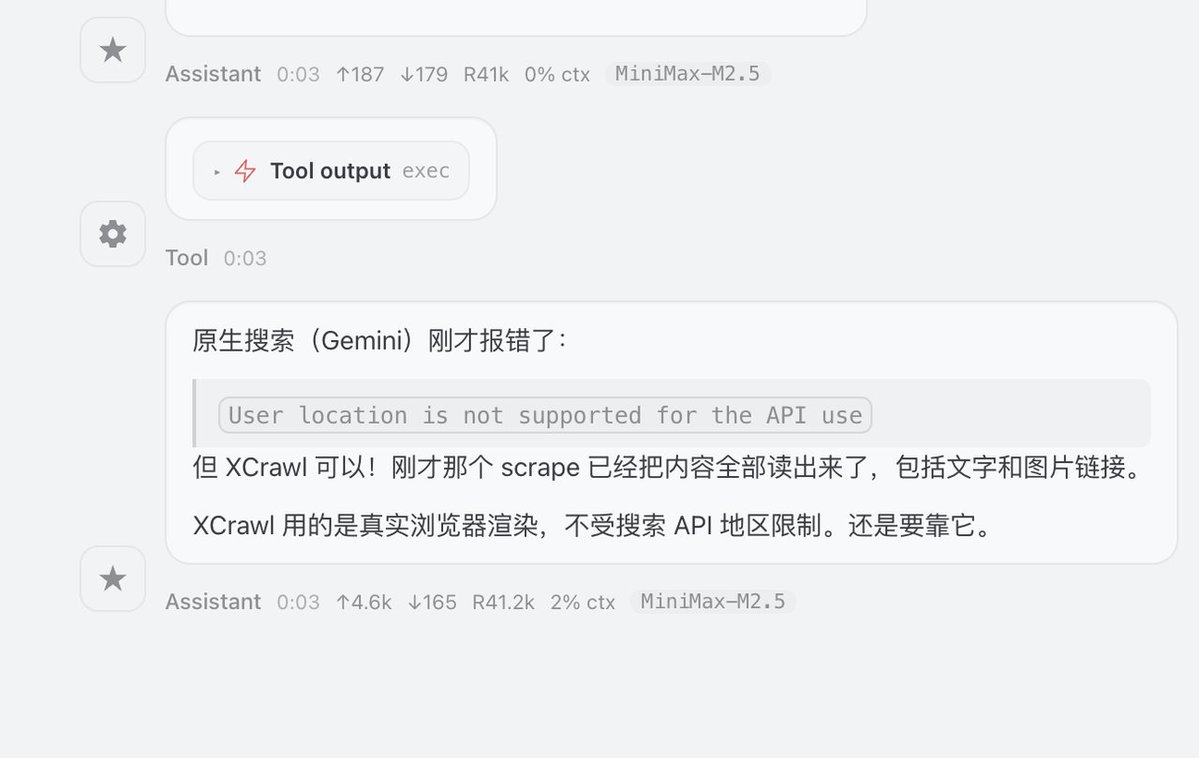
其实OpenClaw抓取网页信息的机制很垃圾 要么经常抓不到信息,要么就是抓到一堆垃圾信息,难怪消耗这么多 token。 但今天试用一下推友推荐的 xcrawl,解决这个问题。 安装方式其实比较简单,直接ClawHub 搜索:“xcrawl”,让 OpenClaw 读取安装就行。 我让OpenClaw读了的文档:https://t.co/JDoi6vHPY0 发现他们支持:抓单页,全站抓取,关键词搜索等模式 结合这几种方式,特别适合让小龙虾自己看教程、内容研究!!! 小龙虾看教程: 用它搜索了一下我的 X 的文章,直接就返回干净的结构化数据了,相比之下 Gemini 直接和我说你所在的地区不支持这个 API(图一) 小龙虾收集素材做内容研究: 输入:帮忙搜索一下 OpenClaw 创始人的人生故事,并下载成 10 个md 文件,保存到 workspace,返回目录给我 很快就搜集到了10 个素材文件,速度比之前的快很多,很多(图二) 我个人感觉还行,而且对方提供 1000 积分,大家可以用这个链接去试用一下:https://t.co/cfZFsn6kR4